
Rhea Mirchandani and Steve Blaxland
Supervisors are responsible for ensuring the safety and soundness of firms and avoiding their disorderly failure which has systemic consequences, while managing increasingly voluminous data submitted by them. To achieve this, they analyse metrics including capital, liquidity, and other risk exposures for these organisations. Sudden peaks or troughs in these metrics may indicate underlying issues or reflect erroneous reporting. Supervisors investigate these anomalies to ascertain their root causes and determine an appropriate course of action. The advent of artificial intelligence techniques, including causal inference, could serve as an evolved approach to enhancing explainability and conducting root cause analyses. In this article, we explore a graphical approach to causal inference for enhancing the explainability of key measures in the financial sector.
These results can also serve as early warning indicators flagging potential signs of stress within these banks and insurance companies, thereby protecting the financial stability of our economy. This could also bring about a considerable reduction in the time spent by supervisors in conducting their roles. An additional benefit would be that supervisors, having gained a data-backed understanding of root causes, can then send detailed queries to these companies, eliciting improved responses with enhanced relevance.
An introduction to Directed Acylic Graph (DAG) approaches for causal inference
Causal inference is essential for informed decision-making, particularly when it comes to distinguishing between correlations and true causations. Predictive machine learning models heavily rely on correlated variables, being unable to distinguish cause-effect relationships from simply numerical correlations. For instance, there is a correlation between eating ice cream and getting sunburnt; not because one event causes the other, but because both events are caused by something else – sunny weather. Machine Learning may fail to account for spurious correlations and hidden confounders, thereby reducing confidence in its ability to answer causal questions. To address this issue, causal frameworks can be leveraged.
The foundation of causal frameworks is a directed acyclic graph (DAG), which is an approach to causal inference frequently used by data scientists, but is less commonly adopted by economists. A DAG is a graphical structure that contains nodes and edges where edges serve as links between nodes that are causally related. This DAG can be constructed using predefined formulae, domain knowledge or causal discovery algorithms (Causal Relations). Given a known DAG and observed data, we can fit a causal model to it, and potentially answer a variety of causal questions.
Using a graphical approach for causality to enhance explainability in the finance sector
Banks and insurance companies regularly submit regulatory data to the Bank of England which includes metrics covering various aspects of capital, liquidity and profitability. Supervisors analyse these metrics, which are calculated using complex formulae applied to this data. This process enables us to create a dependency structure that shows the interconnectedness between metrics (Figure 1):
Figure 1: DAG based on a subset of banking regulatory data
The complexity of the DAG highlights the challenge in deconstructing metrics to their granular level, a task that supervisors have been performing manually. A DAG by itself, being a diagram, does not have any information about the data-generating process. We leverage the DAG and overlay causal mechanisms over it, to perform tasks such as root cause analysis of anomalies, quantification of parent nodes’ arrow strengths on the target node, intrinsic causal influence, among several others (Causal Tasks). To support these analyses, we have leveraged the DoWhy library in Python.
Methodology and performing causal tasks
A causal model consists of a DAG and a causal mechanism for each node. This causal mechanism defines the conditional distribution of a variable given its parents (the nodes it stems from) in the graph, or, in case of root nodes, simply its distribution. With the DAG and the data at hand, we can train the causal model.
Figure 2: Snippet of the DAG in Figure 1 – ‘Total arrears including stage 1 loans’
The first application we explored was ‘Direct Arrow Strength’, which quantifies the strength of a specific causal link within the DAG by measuring the change in the distribution when an edge in the graph is removed. This helps us answer the question – ‘How strong is the causal influence from a cause to its direct effect?’. On applying this to the ‘Total arrears including stage 1 loans’ node (Figure 2), we see that the arrow strength for its parent ‘Total arrears excluding stage 1 loans’ has a positive value. This can be interpreted as removing the arrow from the parent to the target will increase the variance of the latter by that same positive value.
A second aspect explored is the intrinsic causal contribution, which estimates the intrinsic contribution of a node, independent of the influences inherited from its ancestors. On applying this method to ‘Total arrears including stage 1 loans’ (Figure 2), the results are as follows:
Figure 3: Intrinsic contribution results
An interesting conclusion here is that ‘Total arrears excluding stage 1 loans’ which had the highest direct arrow strength above, actually has a very low intrinsic contribution. This makes sense because it is calculated as a function of ‘Assets with significant increase in credit risk but not credit-impaired (Stage 2) 30 90 days’, that have a high intrinsic contribution as seen in Figure 3 and are driving up the direct arrow strength for ‘Total arrears excluding stage 1 loans’ that we saw above.
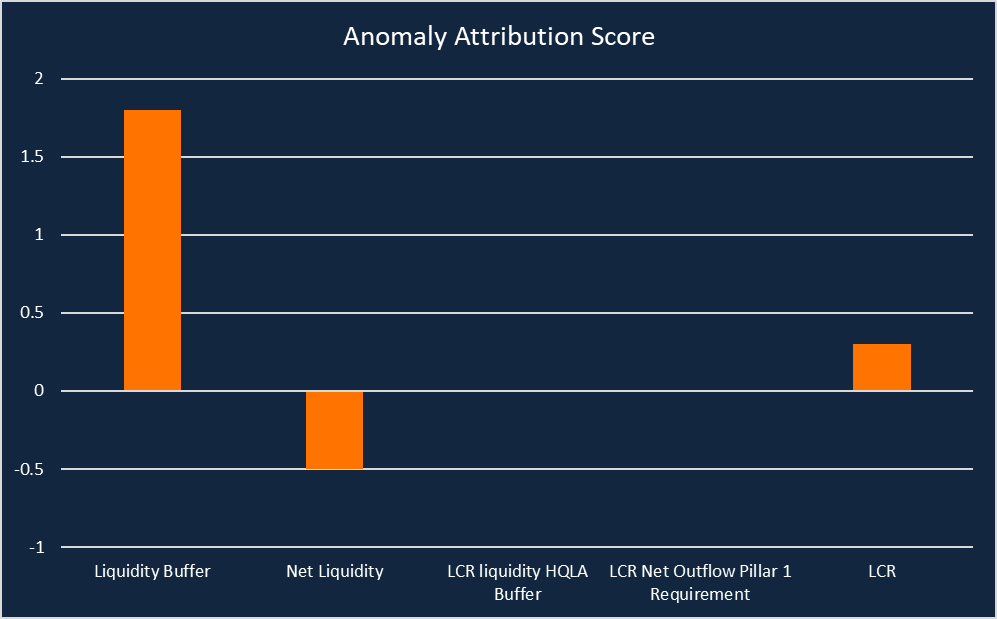
Another area of focus for a supervisor is to attribute anomalies to their underlying causes, which helps answer the question ‘How much did the upstream nodes and the target node contribute to the observed anomaly?’. Here, we use invertible causal mechanisms to reconstruct and modify the noise leading to a certain observation. We have evaluated this method for an anomalous value of the liquidity coverage ratio (LCR), which is the ratio of a credit institution’s liquidity buffer to its net liquidity outflows over a 30 calendar day stress period (Annex XIV). Our results showed that the anomaly in the LCR is mainly attributed to the liquidity buffer (which feeds into the numerator of the ratio) (Figure 4). A positive score means the node contributed to the anomaly, while a negative score indicates it reduces the likelihood of the anomaly. On plotting graphs for the target and the attributed causes, they had very similar trends affirming that the correct root cause had been identified.
Figure 4: Anomaly attribution results
Limitations
Well-performing causal models require a DAG that correctly represents the relationships between the underlying variables, otherwise we may get distorted results, providing misleading conclusions. Another critical task is to decide the correct level of granularity for the data set used for modelling, which includes determining whether separate models should be fit on each organisation’s data, or a more generic data set is preferred. The latter might yield inaccurate results since each company’s business model and asset/liability compositions differ significantly, causing substantial variation in the values represented by each node across the different companies’ DAGs, which makes it difficult to generalise. We might be able to group similar companies together, but that is an area we are yet to explore. A third area of focus is validating the results from causal frameworks. As with scientific theories, the result of a causal analysis cannot be proven correct but can be subject to refutation tests. We can apply a triangulation validation approach to see if other methods point to similar conclusions. We attempted to further validate our assumption about the need for causal relationships in the data over mere correlations, by using supervised learning algorithms, calculating the SHAP values to see if the most important features differ from the identified drivers using the causal inference. This approach reaffirmed the fundamental purpose of causal analysis, as the features with the highest SHAP values were the ones that had the highest correlations with the target, regardless of whether they were causally linked. However, we are looking at exploring triangulation validation in further detail.
Conclusions
Moving beyond correlation-based analysis is critical for gaining a true understanding of real-world relationships. In this article, we showcase the power of causal inference and how it might contribute to the delivery of judgement-based supervision.
We discuss how causal frameworks can be used to conduct root cause analysis to identify key drivers for anomalies, that could be signs of concern for an organisation. This could also point to erroneous data from companies and supervisors can request resubmissions, thereby improving the data quality. We have also tapped into quantifying the causal influence for metrics of interest, to get a better idea of the factors driving various trends. An impressive feature is the ability to quantify the intrinsic contributions of variables, after eliminating the effects inherited from their parent nodes. The advantage of this causal framework is that it is easily scalable and can be extended to all companies in our population. However, there are concerns around the validity of the results from causal algorithms as there is no single metric (such as accuracy) to measure performance.
We plan to explore a wide variety of applications that can be performed through these causal mechanisms, including simulating interventions and calculating counterfactuals. As organisations like ours continue to grapple with ever-growing volumes of data, causal frameworks promise to be a game-changer, paving the path for more efficient decision-making and an optimal utilisation of supervisors’ time.
Rhea Mirchandani and Steve Blaxland work in the Bank’s RegTech, Data and Innovation Division.
If you want to get in touch, please email us at [email protected] or leave a comment below.
Comments will only appear once approved by a moderator, and are only published where a full name is supplied. Bank Underground is a blog for Bank of England staff to share views that challenge – or support – prevailing policy orthodoxies. The views expressed here are those of the authors, and are not necessarily those of the Bank of England, or its policy committees.
Share the post “Using causal inference for explainability enhancement in the financial sector”
Publisher: Source link








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}